
Tag: net neutrality

For those of you that missed it:
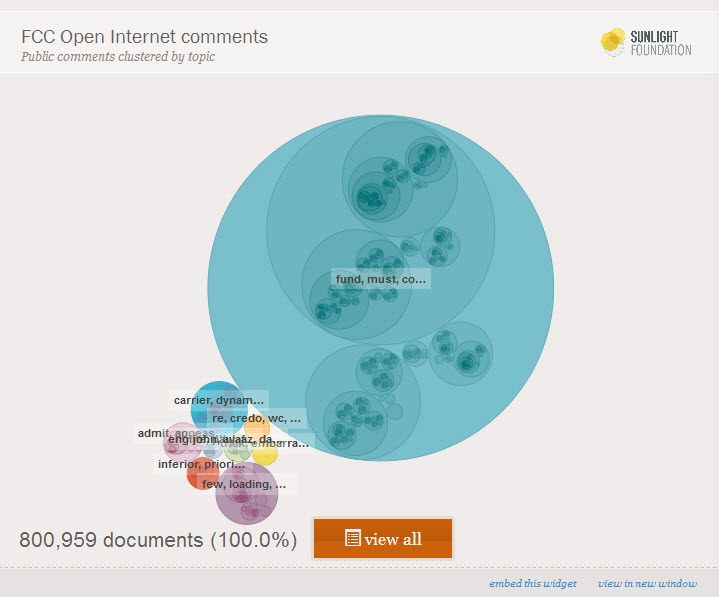
On Aug. 5, the Federal Communications Commission announced the bulk release of the comments from its largest-ever public comment collection. We’ve spent the last three…
"You Two! We're at the end of the universe, eh. Right at the edge of knowledge itself. And you're busy… blogging!" — The Doctor, Utopia
For those of you that missed it:
On Aug. 5, the Federal Communications Commission announced the bulk release of the comments from its largest-ever public comment collection. We’ve spent the last three…