Come on people!
Time for another rant.
If you've ever stuck a CD into your computer and had your player program magically tell you the name of the album, the artist, and all the track information, then you're familiar with the Gracenote (formerly known as the CD Database, CDDB). This is a generally useful collection of data about CDs totally created by volunteers. How is the data gathered? Well, whenever you put a CD into your computer and the program fails to fill in the information, you can fill it in and then submit the data back up to the larger collective. Here's my beef: I'm sick and tired of the number of basic mistakes in the data. The number of mistakes I've run into recently leads me to believe there is no quality control at all. Here's my first example:
Incorrect:
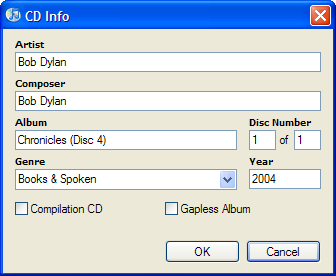
In this case someone thought that the name of the album was "Chronicles (Disc 4)" which was "disc 1 of 1" in a set of one. Sorry folks, but the name of the Album is "Chronicles" and this happens to be disc 4 of a 6-disc set. Additionally, this is a book on CD. They don't have composers! (Nor, folks is the name of the person reading the book considered a composer. The number of times I've seen that.)
Correct:
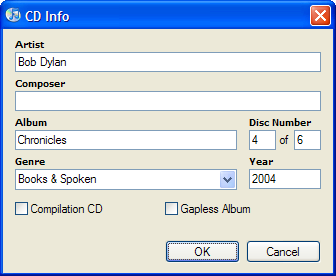
My other example:
Incorrect:

In this case someone has decided that the author's name is "Cynthia Lennnon", the name of the album is "Lennon 1" and that this is a "Compilation CD". Well, I'd forgive the misspelling of her name (I'm hardly one to be able to complain about that,) but it carries through all nine CDs. They got the "disc 1 of 9" correct but still insisted on misnaming the album itself. And finally, compliation CD are albums with multiple artists, typically a different one for each track. Sorry, this is another book on CD, there is only one artist. (If it was an anthology by multiple authors then this option should be checked.)
Correct:
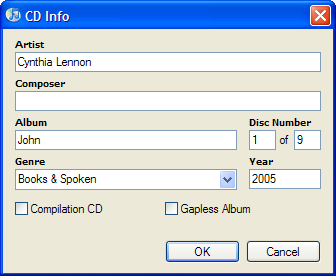
Just had to get that off my chest.
posted by Michael @ 8:33 AM
1 Comments
![]()



